
Greetings, fellow travelers!
I wanted to take some time today to talk about MongoDB Stitch, a new back-end-as-a-service offering by MongoDB, and walk through making a simple web page to view GitHub Issues.
If you are unfamiliar with MongoDB or other Document Store databases, I highly recommend you take some time to read more about the differences between the different database types, go through MongoDB’s Getting Started guide, or even take one of the awesome courses offered via MongoDB University.
Fortunately for us, since MongoDB Stitch is a back-end-as-a-service, we don’t need to be experts in setting up and administrating a MongoDB database; they’ll do it for us!
Note: MongoDB Stitch is still in beta. Some of these features I describe may change before their 1.0 release.
We’ll need a few things:
- A MongoDB Stitch Account
- A MongoDB Atlas Account (creating a Stitch Account will create an Atlas Account)
- The MongoDB cli (optional)
- A GitHub Account
- A GitHub Repository you manage and can create webhooks on
- Your Favorite Text Editor
The Goal
We’re going to create a web page that displays a list of created issues in a set of GitHub repositories. When an issue is created in GitHub, it will fire a webhook to our Stitch application, which will massage the data some before storing it in the Atlas database. Finally, the web page will access the Stitch Atlas service to list the issues.
Let’s get started.
Create a Stitch and Atlas Account
Getting started with Stitch is simple. Head over to their landing page and click on the “Get Started Free” option. This will walk you through creating a Stitch and an accompanying Atlas Account and Cluster. If you have any questions on this stage I highly recommend you look through their documentation on getting started with Atlas, and creating a cluster. Their explanation is concise and easy to follow.
Create Your Stitch Application
Getting started with a new Stitch Application is as simple as logging into the portal, clicking “Create New Application,” and giving it a name and cluster! For this, I will be creating a Stitch Application called GithubIssueList and assigning it to my AdvPlatCluster Atlas cluster.
Note: if you just created this cluster, you may have to wait a few minutes for it to show up in the list, as the cluster may still be constructing itself.
Authentication and an API Key
Once complete, you’ll be taken to your App’s Getting Started page. The first thing we will need to do is turn on Authentication. Anonymous Authentication is a great way to get started, but not a great way to build a secure application. Let’s go to the sidebar under “Control” and navigate to the “Authentication” page.
We’ll enable API Keys for authentication and make a new API Key: GHApiKey.

Take note of the API Key and the User’s ID field. We’ll be using them both later.
Set up the Database
Now we’ll need a place in our cluster to store the data. Let’s navigate to the Atlas Cluster’s section in the sidebar, click on the cluster we linked earlier, and then on the “Rules” tab. You’ll see there is already a collection created for you of format app-{someNumbers}.items. We’ll create a new one for the database ghdata and the collection issues. 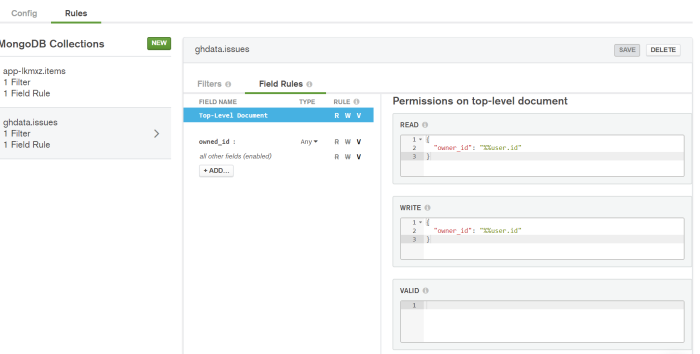
When we receive our webhook data from GitHub, this is the database and collection we’ll put the documents into.
You’ll notice that we have some preconfigured permissions. By default, both read and write permissions are allowed if the document’s owner_id field is equivalent to %%user.id. We should know that %%user is a special expansion that can be used in Stitch Rules and Pipelines. For our purposes, when querying the database via Stitch while authenticated with our API Key, we will only be able to read or write documents whose owner_id field is equal to the User ID field we wrote down earlier.
You’ll notice there is also a Filter tab. This, too, comes preconfigured:
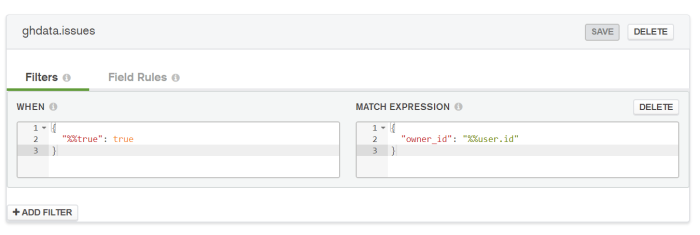
The default filter says “When true, only show documents whose owner_id field is equal to the current User’s ID field”.
We should note that filters are applied before rules are. This means that even if we remove the preconfigured Read and Write rules around owner_id, we would still be unable to read another User’s documents as the Filter would exclude them before the Rules could be evaluated.
At this point you might want to connect to your Atlas cluster to ensure you have solid connectivity and your IP address is whitelisted.
Set up GitHub Integration
With our User Created and our Database up and running, we need to allow our Stitch application to receive data from GitHub. In the sidebar under Services, click “Add a Service”, choose GitHub and give it a name (I am calling mine IssueService).
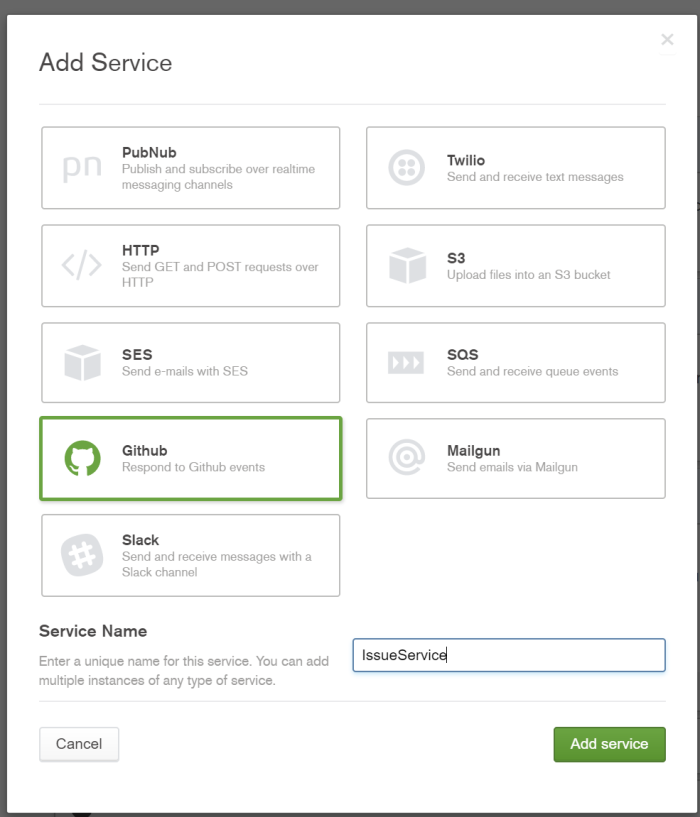
With our IssueService created, we will add an Incoming Webhook to it. Give the Incoming Webhook a name, and a secret.
Be sure to take note of the secret as we will need it when we configure the GitHub repository to send us information.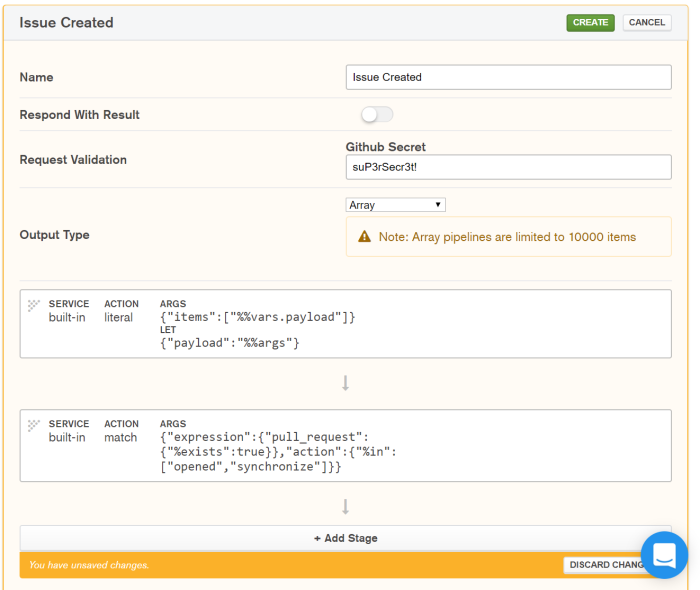
The Webhook Pipeline
Once again, Stitch has set up a nice set of default stages in the pipeline. Pipelines are sequences of actions defined in JSON. Taken from their documentation:
- Pipelines are written in simple JSON.
- Pipelines can be constructed in the UI and referenced by name in code, or coded directly with SDKs.
- Pipelines can use expansions to pass information from one stage to another or incorporate information from outside the pipeline stage
- Information can be passed from one stage to another with let.
- Information about requesting user can be incorporated with
%%user.- Global variables can be defined in Stitch and referenced with %%values.
- Information about the current or prior state of a document or field can be incorporated through MongoDB expansions.
- Some services like Twilio can execute a pipeline as a response to an incoming webhook.
The default pipeline for the GitHub incoming webhook has two stages: a literal stage, which binds data coming in from the webhook’s body, and a match stage, which takes the data passed to it from the literal stage and filters it based on an expression. This match stage checks to see if the property “pull request” exists in the document and if the value stored in the property “action” is “opened” or “synchronize”.
For example, this document would pass the match expression:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "pull_request" : { | |
| }, | |
| "action": "opened" | |
| } |
But this one would not:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "pull_request":{ | |
| }, | |
| "action":"closed" | |
| } |
While this is great for pull requests, we are interested in tracking issues, so let’s edit the default mapping action to the following:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "expression": { | |
| "issue": { | |
| "%exists": true | |
| } | |
| }, | |
| "action": { | |
| "%in": [ | |
| "opened" | |
| ] | |
| } | |
| } |
This states that we only want to match documents who have a property called “issue” and whose “action” property is “opened”. If we allow “synchronize” events, we may wind up with duplicate data in our database.
With that, our pipeline is ready to receive valid GitHub issue open webhook events, but aside from filtering the data, our pipeline isn’t doing much with it. Let’s look at the Issue Event payload from GitHub. There is a lot of data in there, and while we have the 25 GB Free tier of hosting, it is wasteful to store all that extra data we won’t be using.
Projecting the Data
To filter down some of the unused data, let’s add a new stage to our pipeline, and change its action to “project“. We’ll use this projection action to include only the fields in our document we want. In particular, we will include:
- issue.html_url
- issue.id
- issue.title
- issue.comments
- issue.created_at
- repository.name
- repository.html_url
This will cut down our data usage significantly.
We do so by defining the following in the event:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "projection": { | |
| "issue.html_url": 1, | |
| "issue.id": 1, | |
| "issue.title": 1, | |
| "issue.comments": 1, | |
| "issue.created_at": 1, | |
| "repository.name": 1, | |
| "repository.html_url": 1, | |
| } | |
| } |
At this point our pipeline should look like this:
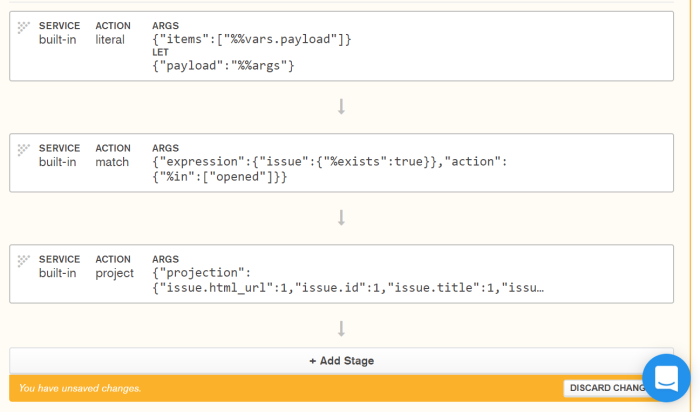
We accept the documents, filter them, and then we map the unnecessary fields away. There are two last steps we need to complete:
- Give our documents an Owner
- Insert the documents into our database
Give the Data an Owner
Adding an owner_id field to our data requires a new stage in our pipeline. Let’s create a new stage whose action is “expr” or expression. Expression stages allow documents to be filtered and then modified before being passed on to the next stage. We’ll first need to enable the “Bind to %%vars” toggle in our stage and insert
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "issue": "%%item" | |
| } |
as the content. Next, we will set the main body of the expression to be
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| { | |
| "expression": { | |
| "owner_id": "<API USER ID HERE>", | |
| "issue": "%%vars.issue" | |
| } | |
| } |
where <API USER ID HERE> is replaced by the value of the ID field for the Api User we created earlier. This returns a whole new document with two top level fields owner_id and issue, with the value of the issue field set to the output of our projection.
Insert the Data into the Database
The final stage we need to add is the easiest! Hit “Add Stage” one more time and
- Change the “Service” drop down from
built-intomongodb-atlas - Change the Action from
findtoinsert - Modify the Database value to
ghdata - Modify the Collection value to
issues
In the end it should look like this:
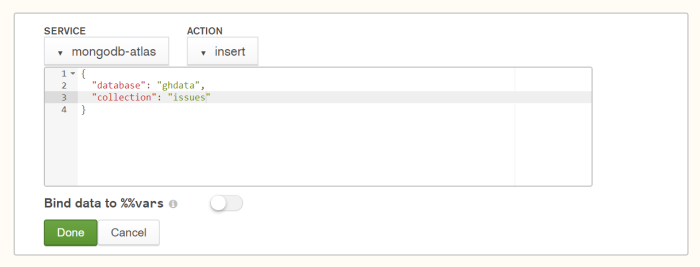
This will connect to our Atlas service and insert the document into the issues collection of the ghdata database.
And we are done! Hit create and your pipeline should look like this and be ready to accept incoming webhooks:

Configuring GitHub
Before we jump over to GitHub, you should notice that creating your incoming webhook provided you a webhook url:

Copy it to your clipboard, and head over to a GitHub repository you want to enable this webhook with. Click on Settings, then Webhooks and the “Add webhook” button.
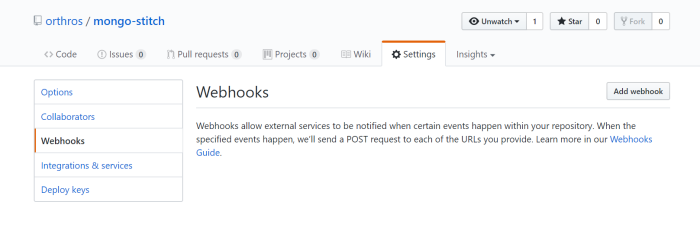
Paste your webhook url into the Payload Url field, change the Content Type drop down to application/json, and set your secret to the secret you configured in your Stitch Application.
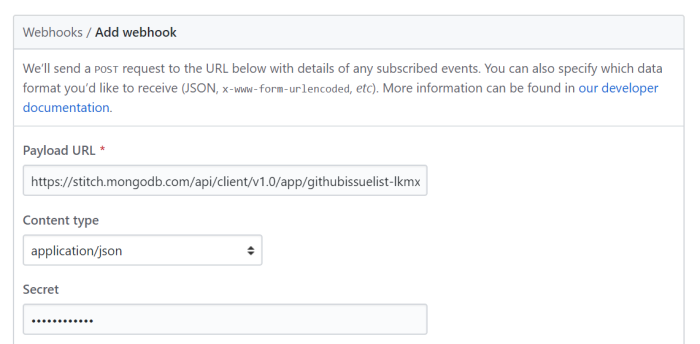
Next, choose “Let me select individual events”, uncheck the “Pull Request” option, and check the “Issues” option.
Finally, hit “Add Webhook” to enable it!
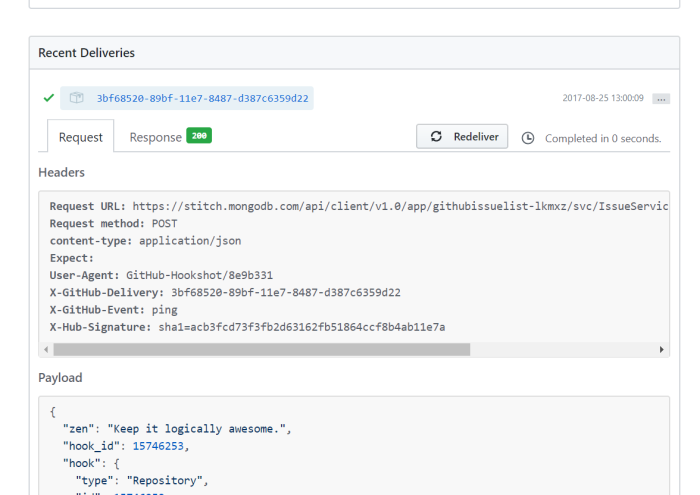
If you click on the webhook and scroll to the bottom of the page, you can see a “Recent Deliveries” section. You can click on each of those identifiers to see if our pipeline returned an error code and what the request looked like.
Making a new Issue
At this point we have our Stitch Application up and running, ready to receive data, and our GitHub repository is ready to push it on new events! Let’s open a new GitHub issue on our repository to see what happens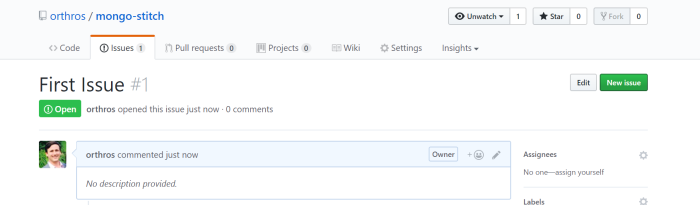
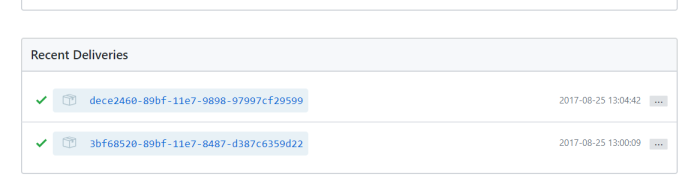
The recent deliveries shows a success
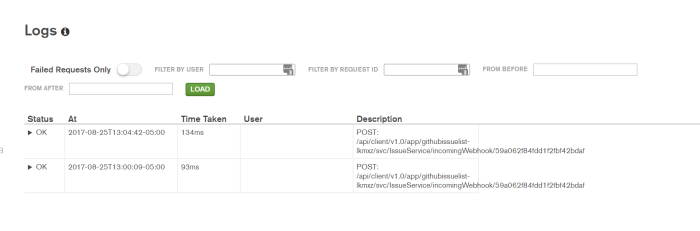
And the Logs console in our Stitch Application show success as well!
Right now if you were to connect to your Atlas cluster use the ghdata db and run db.issues.find().pretty() you would see something like:
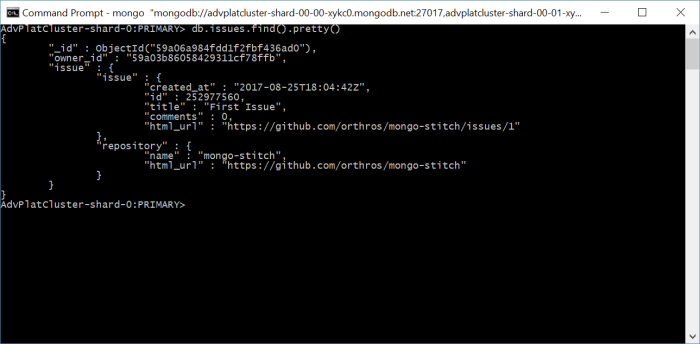
Our data made it all the way through!
Writing the Web Page
The lion’s share of our journey is over. All we need is to write a web page to connect to the Stitch Service and view the data. You can use any framework you like as there are Stitch clients for Node, Javascript, Java, and Swift, but I’m going to write a simple static HTML page suitable for a custom “New Tab” page in your browser. If you want to skip to the end, you can check out the final code in my GitHub repository.
Our page will have a simple title and a div placeholder where we will insert the list of issues we get back from our Stitch Application.
Outline
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| <html> | |
| <head> | |
| <link rel="stylesheet" href="../static/css/bootstrap.min.css"> | |
| <script src="../static/scripts/stitch.min.js"></script> | |
| <script src="../static/scripts/config.js"></script> | |
| <script> | |
| displayIssuesOnLoad() { | |
| //Connect to stitch then display issues | |
| } | |
| displayIssues(){ | |
| //Updatethe issues div | |
| } | |
| </script> | |
| </head> | |
| <body onLoad="displayIssuesOnLoad()"> | |
| <div class="container"> | |
| <br/> | |
| <h3 class="text-center">Current GitHub Issues</h3> | |
| <div class="container-fluid" id="issues"> | |
| </div> | |
| </div> | |
| </body> | |
| </html> |
I’ve downloaded the Bootstrap css files as well as the Stitch driver so I won’t need online access to them (since this will be a “New Tab” page). I’m also including a config.js file in which I’ll define some constant variables to use.
The config.js is there to expose a number of const variables to use when logging in.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| const APP_ID = "githubissuelist-lkmxz"; | |
| const APP_DB = 'ghdata'; | |
| const APP_COLLECTION = 'issues'; | |
| const APP_API_KEY = '<YOUR API KEY HERE>'; |
The APP_DB and APP_COLLECTION variables come from the database and collection we are storing our issues in.
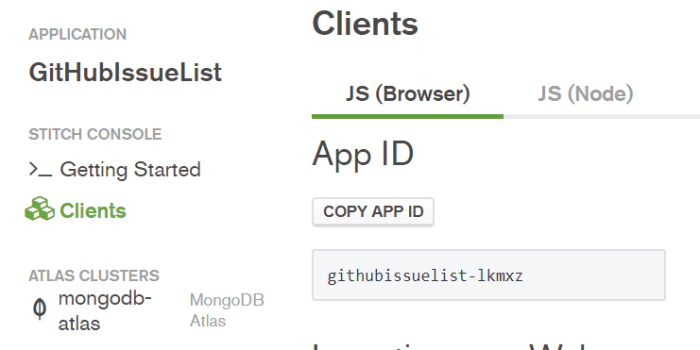
APP_ID is the unique identifier of your Stitch App. You can find it on the Stitch console in the “Clients” sidebar.
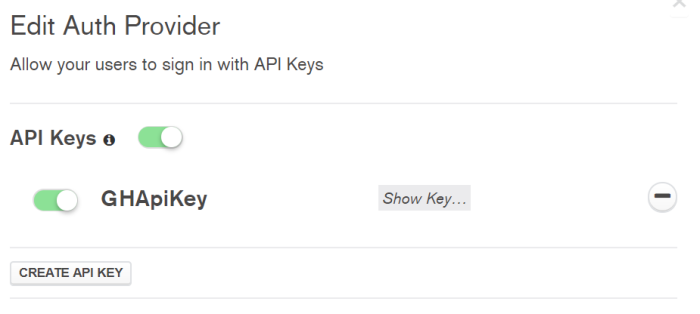
APP_API_KEY is the API Key the client will use to authenticate with the Stitch Service. You can get the key by going to the Authorization page, editing the API Keys authorization provider, and hitting “Show Key” on the API Key you wish to use.
Finally, we can write the Javascript client code:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| const client = new stitch.StitchClient(APP_ID); | |
| const db = client.service('mongodb', 'mongodb-atlas') | |
| .db(APP_DB); | |
| function displayIssuesOnLoad() { | |
| client.authenticate('apiKey', APP_API_KEY) | |
| .then(displayIssues); | |
| } | |
| function displayIssues() { | |
| db.collection(APP_COLLECTION) | |
| .find({ }, { limit: 10 }) | |
| .then(docs => { | |
| console.log(docs); | |
| var html = docs.map(c => `<div class="center-block"> | |
| <hr> | |
| <div class="center-block text-center">Issue: <a href="${c.issue.issue.html_url}">${c.issue.issue.title}</a></div> | |
| <div class="text-center">Comments: ${c.issue.issue.comments}</div> | |
| <div class="text-center"> | |
| Repository: | |
| <a href="${c.issue.repository.html_url}">${c.issue.repository.name}</a> | |
| </div> | |
| <hr> | |
| </div>`) | |
| .join(""); | |
| document.getElementById("issues").innerHTML = html; | |
| }); | |
| } |
In these two functions we do the following:
- New up a
StitchClientconnected to our Stitch Application - Request a connection to a MongoDB Atlas service and get the database
- Authenticate using our API Key
- Query the
issuescollection for all documents (but limiting it to 10) - Log the documents (because debugging is fun!)
- Write some html for each document we received
- Set the inner content of the
divnamed “issues” to our generated html
This should give us:
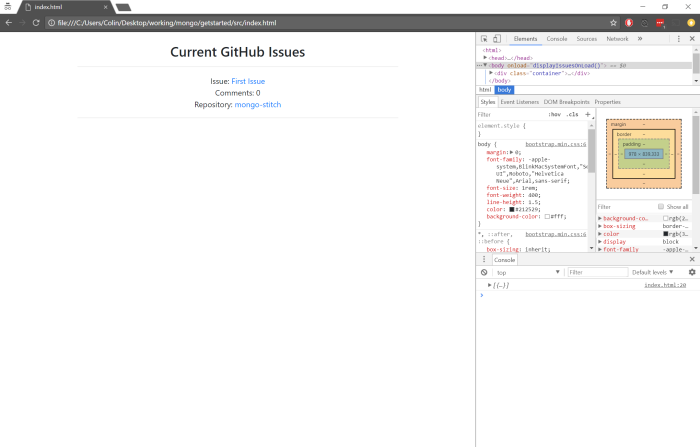
We did it!
So What Have We Accomplished?
We’ve managed to accomplish a lot, if you’ve been following along:
- Set up a new MongoDB Database hosted in the cloud via Atlas
- Created a Stitch Application
- Secured the Application via API Keys, database rules, and filters
- Set the Application to respond to incoming webhook events by updating a database
- Configured a GitHub repository to provide events when an issue is created
- Wrote a Web page to connect to our Stitch Application and display the data in it.
Where Do We Go from Here?
- Spruce up the Web Page UI
- Write the Web Page in a full framework like MVC, Spring,or Angular
- Write Another WebHook for Issues being deleted to remove them from the database
- Write a mobile App to view the Issues using the Java or Swift Clients
- Connect the GitHub Pipeline you made to another Pipeline (like Twilio or Slack)
- Build your own App!
Stitch is a powerful and flexible back-end-as-a-service. As it grows out of beta and connects to more services and pipelines, I can’t wait to see what we can build!
Happy coding!
